The puzzles in Super Lucky’s Tale and New Super Lucky’s Tale aren’t exactly groundbreaking, but their clean, grid — based structure intrigued me. Could I automate solving them? Sure, I could’ve just solved them by hand — they’re simple enough — but where’s the fun in that?
That’s how Unfox came to life. It’s a small project to programmatically solve these puzzles, giving me an opportunity to explore algorithms, Rust, and a few unexpected insights about performance optimization along the way.
Introduce the puzzle: How Do These Puzzles Work?

In these puzzles, you control a board with pawns (foxes and monsters) that move until they hit an obstacle. Your task is to guide all the foxes to their respective goal points.
The key rules:
- Pawns can move in four directions: up, down, left, and right.
- A pawn continues moving in a straight line until it hits a wall or another pawn.
- Monsters serve as movable obstacles but don’t need to reach any specific location.
- The grid itself remains static throughout the puzzle.
The complexity arises from the fact that moving one pawn often sets up (or blocks) the path for others. It’s a satisfying logic problem, and while the puzzles aren’t difficult, they were a great foundation for building an automated solver.
My observation was clear: there are a finite number of possibilities. 🎯
Choosing search algorithm, BFS vs DFS
When designing the algorithm, I had a choice: DFS or BFS? The difference between the two wasn’t huge in this case, given the simplicity of the puzzles. Both would’ve worked just fine.
But let’s return to theory for a moment. What are these algorithms? 🧩
- DFS (Depth-First Search): It explores as far as possible along each branch before backtracking. It’s often used in scenarios where the search space is large, and you want to find a solution quickly.
- BFS (Breadth-First Search): It systematically explores all moves layer by layer, ensuring it finds the shortest solution.
But since the puzzles were simple and I could afford a bit of extra computation, I went with BFS (Breadth-First Search). DFS, while faster in some scenarios, doesn’t guarantee optimality, and I figured - why not aim for the shortest path if I could?
In hindsight, the decision didn’t drastically impact performance because the search space was limited. But it was a fun opportunity to work with BFS and see it in action on a small-scale problem.
How Does Unfox Solve Puzzles?
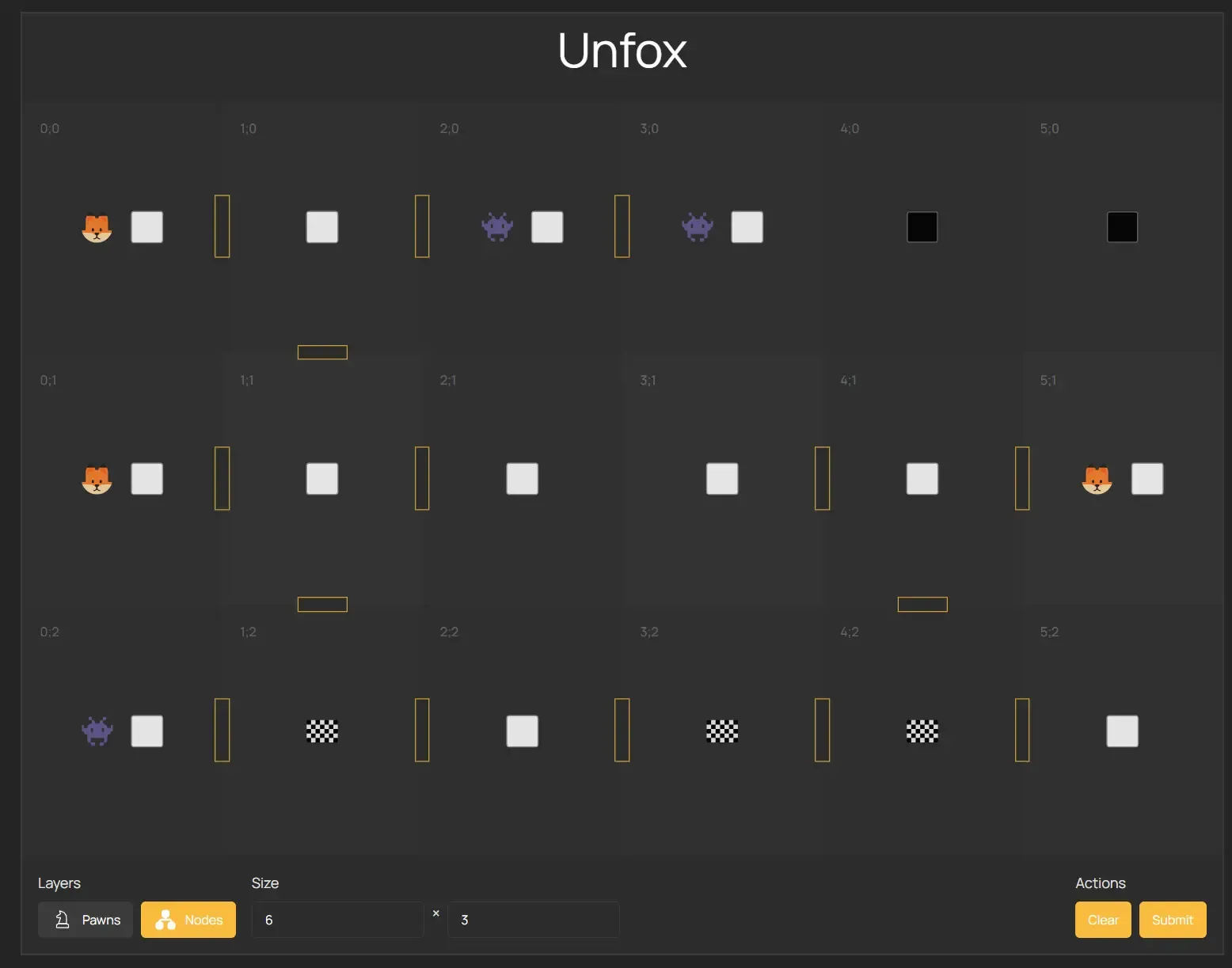
Unfox represents the puzzle as a grid, where each cell has attributes like:
- Type: Wall, empty space, or goal.
- Pawn: Fox, monster, or nothing.
How it works, step by step:
- Describe the Puzzle: Here I found the GUI in the form of a frontend in Svelte strongly useful. It allows you to describe all the information with ease. The GUI allows you to describe the puzzle in detail: the puzzle can have any size, each field can have any pawn, each field can have any type (goal, normal, wall) and each field can have any edges that describe the allowed paths between fields.
- Sending the Puzzle to the Solver: The GUI sends a query to the backend, which will continue until it finishes solving the puzzle or reaches the move limit. The backend does one puzzle at a time.
- Initialize the Queue: BFS starts with the initial positions of all pawns.
- Simulate Moves: For each possible move (up, down, left, right):
- Slide the selected pawn in the given direction until it hits a wall or another pawn.
- Record the new positions of all pawns after the move - thanks to this, we can easily avoid duplicates.
- Check the Goal: If all foxes are in their respective goals, the puzzle is solved.
- Repeat Until Solved: If the puzzle isn’t solved and the limit of moves hasn’t been reached, repeat the process with the new positions of the pawns.
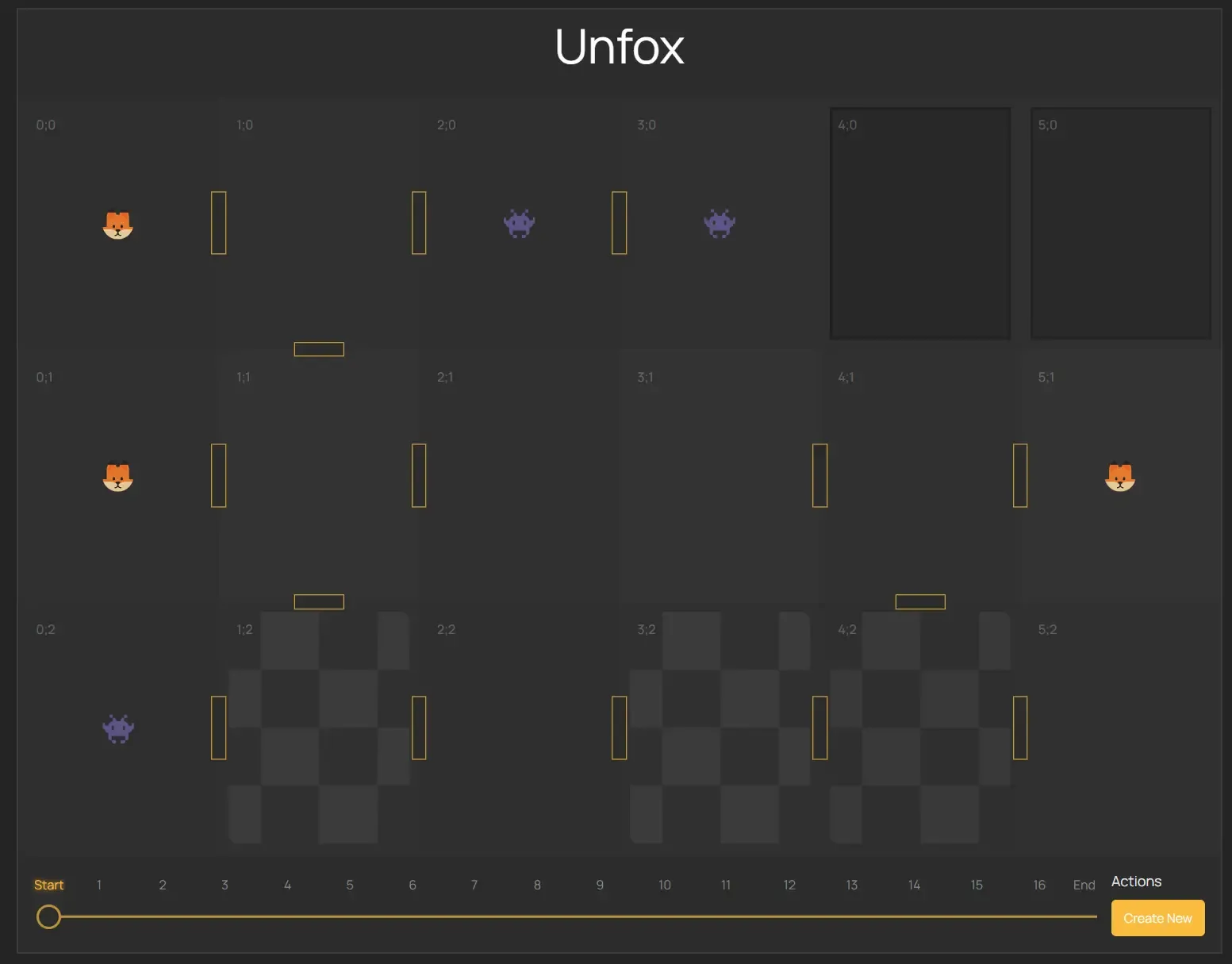
GUI for Solution Preview
I found it helpful to visualize the solution. The GUI allows you to see the solution step by step, showing the moves of each pawn. It’s a great way to understand the algorithm and see how the pawns move in real time. And also it’s a great way to copy the solution to the game itself. 🤣
Preview allows to see the each step of the solution by representation of the chosen branch of the algorithm.
Lessons Learned: Optimizing State Representation
Building Unfox was a deep dive into how design decisions affect both performance and code clarity. Here are the key lessons I took away:
1. HashMaps vs. Vectors: Custom Hashing Matters
Initially, I used a Vec to track the history of visited states in BFS. It seemed like the simplest solution, but as the number of states grew, the performance took a massive hit.
Switching to a HashMap with custom hashing was a game-changer. By hashing only the relevant data — specifically, the positions of the pawns — and ignoring the static parts of the grid, I drastically reduced the overhead of comparisons. For some reason, the improvement felt multiplicative rather than just incremental. This reinforced the importance of tailoring data structures to fit the problem.
2. Separating Static and Dynamic Data
Right now, my implementation treats the grid and the pawn positions as a single unit. This is convenient, but not optimal.
A better approach would’ve been to separate the static grid data (walls, goals) from the dynamic pawn positions. The static data could be precomputed and reused, while the dynamic data could be updated during the BFS traversal. This separation would reduce memory usage and eliminate redundant calculations. While I stuck with the simpler design for convenience, this was a key realization for improving efficiency in future projects.
3. Processor Words Are Faster Than You’d Think
At first, I leaned toward using compact 8-bit containers for data, thinking smaller data sizes would automatically mean faster performance. But the opposite happened: the program slowed down instead of speeding up.
After refreshing my knowledge of how CPUs handle data, I realized that the processor’s word size (e.g., usize in Rust) is the most efficient unit of operation. This is because it avoids alignment adjustments and splits during operations. Switching to processor words improved performance noticeably, even though it felt counter-intuitive given the memory savings smaller containers could theoretically offer. It was a great reminder that optimal solutions depend on the context and hardware specifics.
4. Readable Structures vs. Manual Offsets
I initially thought manually managing offsets in a Vec - where I knew exactly where to find each piece of data - would make the program faster. It seemed logical: less structure means less overhead, right?
Wrong.
It turned out that structural data types with static offsets were significantly faster. Not only were they more readable and easier to work with, but they also performed much better. Why? Because the compiler can calculate and optimize offsets once during compilation, whereas manual offset calculations are repeated every time at runtime.
This was a lightbulb moment: “Readable doesn’t mean slower; sometimes, it’s the opposite.” Structures were faster, clearer, and saved me from manually recalculating offsets repeatedly.
Why Rust and Svelte?
I chose Rust for the backend and Svelte for the frontend not because they were the best tools for the job, but because I wanted to experiment. Rust’s memory safety and performance were perfect for implementing BFS, while Svelte made it easy to build an intuitive interface for inputting puzzles and visualizing solutions. Together, they worked beautifully.
And I know that writing it purely in TypeScript wouldn’t change much in terms of performance since these are such simple puzzles. The choice was heavily driven by the thought, “This is what I’d like to write it in for myself.” 😁👌
Final Thoughts
Unfox started as a curiosity but turned into a great learning experience. From experimenting with BFS to optimizing state representation and understanding the trade-offs of coupling static and dynamic data, this small project taught me a lot about algorithms and performance.
If you’re curious to see it in action — or just want to play around with it — you can check out Unfox on GitHub.